富士通とFQSは7月18日に都内で「ADMEWORKSご紹介セミナー」を開催したが、その場で“KY法”の詳しい解説がなされた。
富士通とFQSは7月18日に都内で「ADMEWORKSご紹介セミナー」を開催したが、その場で“KY法”の詳しい解説がなされた。
富士通とFQSがADMEWORKSに独自のモデル手法を導入
“KY法”で100%のパターン分類を達成、予測精度大幅向上へ前進
2008.08.13−富士通と富士通九州システムエンジニアリング(FQS)は、化合物のさまざまな特性を予測できるモデリングシステム「ADMEWORKS」の最新バージョンに、予測精度を大幅に高める独自の新手法“KY法”(K-step Yard sampling)を導入した。予測モデル構築のためのサンプルデータのパターン分類において、100%の分類率を初めて実現した。最終的なモデルの予測率は、この分類率を超えることができないため、予測精度を高めるためには分類率を引き上げることがポイントになるという。とくに、従来手法で分類率を高めることが難しかった“毒性”をターゲットにして、100%分類を達成できたことに大きな意味があるとしている。
富士通とFQSは7月18日に都内で「ADMEWORKSご紹介セミナー」を開催したが、その場で“KY法”の詳しい解説がなされた。
ADMEWORKS自体は、構造活性相関解析(QSAR)のためのモデル化と予測を行うための統合ソフト。名前どおり、ADME(吸収・分布・代謝・排出)関連を中心とする各種のモデルをあらかじめ搭載しているが、ユーザーが手持ちのデータを使って独自のモデルを構築するための「モデルビルダー」機能も用意されている。
実際のモデル構築の手順としては、構造式と実験データ(予測したい特性)の一群をサンプルとして利用し、化合物の構造特徴を数値的・定量的に表すパラメーターを多数発生させたあと、予測したい特性に関係するパラメーターを抽出(特徴抽出)し、構造と特性の関連を探ってモデル式を組み立てていく。
その過程でさまざまな統計的解析手法を駆使するわけだが、例えば毒性が“ある”か“ない”かといった2クラスの判定の場合、サンプルのデータ空間を線形で分類できるのが理想。ところが、毒性に関しては予測対象化合物の構造変化性がきわめて大きく、サンプルの数も多くなるため、データ空間が複雑になってしまい、強力な非線形の分類手法を使ってもデータ解析的には精度が出にくいという問題があった。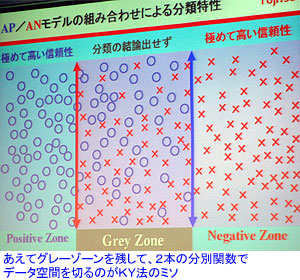
実際、今回“KY法”のテストに用いたエイムス変異原性(6,965サンプル)では、線形最小二乗法で73.5%、SVM(サポートベクターマシン)法で90.87%、AdaBoost法で77.24%の分類率にとどまった。これらを用いて作成したモデル式では、理論的に分類率を上回る予測率は達成できないという。
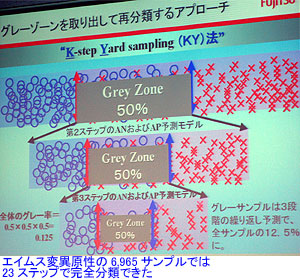
これに対し、“KY法”は同じサンプルデータを用いて、100%の分類率を達成した。この手法は、2本の判別関数を利用(APおよびANモデルの組み合わせ)して、データ空間を分類するのがミソ。中央で分類できないグレーゾーンを取り出して、再分類を繰り返すことにより、全体のグレーゾーンを縮小させていく。今回のエイムス変異原性(6,965サンプル)では、23ステップで100%分類が達成できた。
“KY法”を考案したのは、富士通の湯田浩太郎氏(バイオIT事業開発本部)だが、同氏はさらに予測率を高めるため、サンプル数を8,000に増やし、50ステップまでの分類に取り組むなど、さらに研究を進めている。